 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
量的データを質的にデータにしたり、その逆の変換を知っていると、データ分析でできることが増えます。
1次元クラスタリング をRで実行する時の実施例です。
Rによるデータ分析 では、 量的データを質的データに変換 するための標準的な前処理の方法として、入れていることが多いです。
データの最大値と最小値の間を均等に分割します。
以下に、複数の方法がありますが、入力データの作り方は同じなので、ここにまとめています。
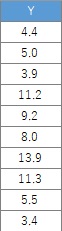
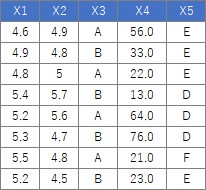
この例では、Cドライブの「Rtest」というフォルダに、
「Data1.csv」という名前でデータが入っている事を想定しています。
ここで使っている35行あります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data1 <- read.csv("Data1.csv", header=T) # データを読み込み
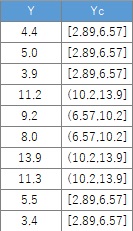
Data1$Yc <- droplevels(cut(Data1$Y, breaks = 3,include.lowest = TRUE))# 3分割する場合。元のデータに質的データを追加する。
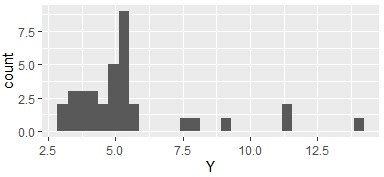
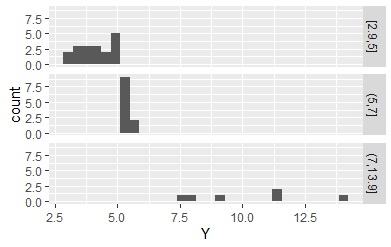
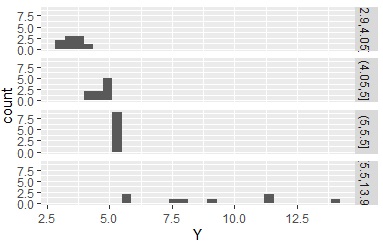
ここで求めた質的データを使って、ヒストグラムを分割すると下のようになります。
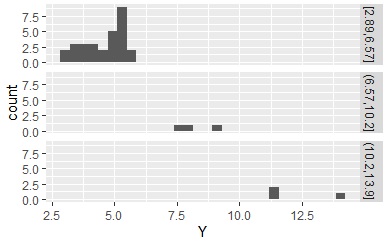
区間を作って、該当するデータがない区間がある場合、 質的データとしてはひとつもないのですが、そういう区間があるという情報は、残っています。 これが残ったままだと、 N進木 を作った時にこの区間がお化けのように現れて来て困ります。 「droplevels」を入れておくと、空の区間については、区間があるという情報が消えます。
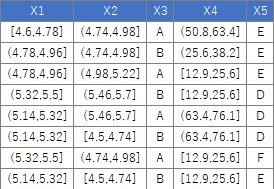
下のようなデータについて、「量的データの列は、質的データにまとめて変換」という処理は、下記でできます。
注意点ですが、例のデータのX4は、小数点以下は0のデータしかないのですが、わざと小数点以下の数字を入れています。
こうしておかないと、X4の列は「numeric」ではなく、「integer」として認識されるので、このコードだと区間ごとの分割が行われません。
ちなみに、「integer」でも分割するように書くと、今度は、最初から「0と1」だけの列にもこの処理が行われてしまい、
良くないです。
これらの問題が起きないようにするコードも作れますが、そうすると、コードが煩雑になるので、ここでは、入力データに気を付けることで対応するようにしています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
for (i in 1:ncol(Data)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "numeric") { # 条件分岐の始まり
Data[,i] <- droplevels(cut(Data[,i], breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
区切りを指定します。
Data1$Yc <- droplevels(cut(Data1$Y, breaks = c(min(Data1$Y),5,7,max(Data1$Y)),include.lowest = TRUE))# 5と7を区切りにする
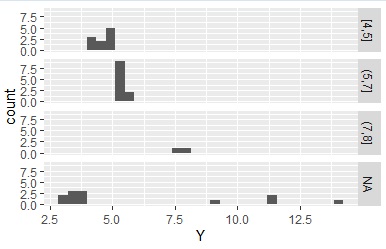
上の例では、minとmaxを区切りの端に下ので全部のデータが指定した区間に入りましたが、
minやmaxを使わないと、区間に入らないデータは「NA]として分類されます。
Data1$Yc <- droplevels(cut(Data1$Y, breaks = c(4,5,7,8),include.lowest = TRUE))# 4、5、7、8を区切りにする
データの区間の区切りを指定する方法の応用です。 最大値、最小値、中央値、2つの四分位値を使うと、各区間に入るデータの数がほぼ25%ずつになります。
Data1$Yc <- droplevels(cut(Data1$Y, breaks = c(min(Data1$Y),quantile(Data1$Y,0.25),median(Data1$Y),quantile(Data1$Y,0.75),max(Data1$Y)),include.lowest = TRUE))# 25%ずつの区切りにする
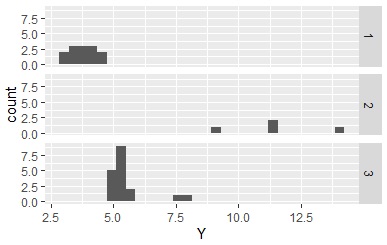
クラスター分析 を使うと、質的データが区間を表すようにならないところが不便です。 ここでは、k-means法を使う場合です。
Data1$Yc <- kmeans(Data1,3)$cluster # k-means法で分類。これは3個のグループ分けの場合
本家のページ
cutの使い方
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/cut
